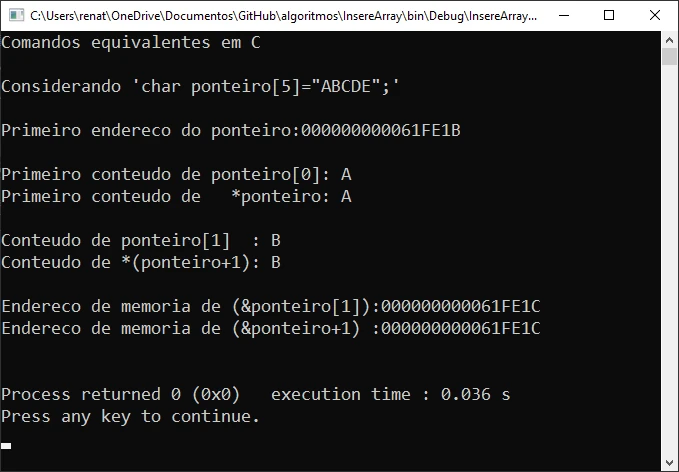
Olha. Eu gostaria de ter aprendido as diversas maneiras de se exibir tanto o endereço de memória como o conteúdo de memória apontado por um ponteiro.
Resumindo, seria mais ou menos o código abaixo. Se faltar alguma coisa, irei adicionando.
#include <stdlib.h>
int main()
{
char ponteiro[5]="ABCDE";
printf("Comandos equivalentes em C\n\n");
printf("Considerando 'char ponteiro[5]=\"ABCDE\";'\n\n");
printf("Primeiro endereco do ponteiro:%p \n\n",ponteiro);
printf("Primeiro conteudo de ponteiro[0]: %c\n",ponteiro[0]);
printf("Primeiro conteudo de *ponteiro: %c\n\n",*ponteiro);
printf("Conteudo de ponteiro[1] : %c\n",ponteiro[1]);
printf("Conteudo de *(ponteiro+1): %c\n\n",*(ponteiro+1));
printf("Endereco de memoria de (&ponteiro[1]):%p\n",(&ponteiro[1]));
printf("Endereco de memoria de (&ponteiro+1) :%p\n\n",(ponteiro+1));
return 0;
}
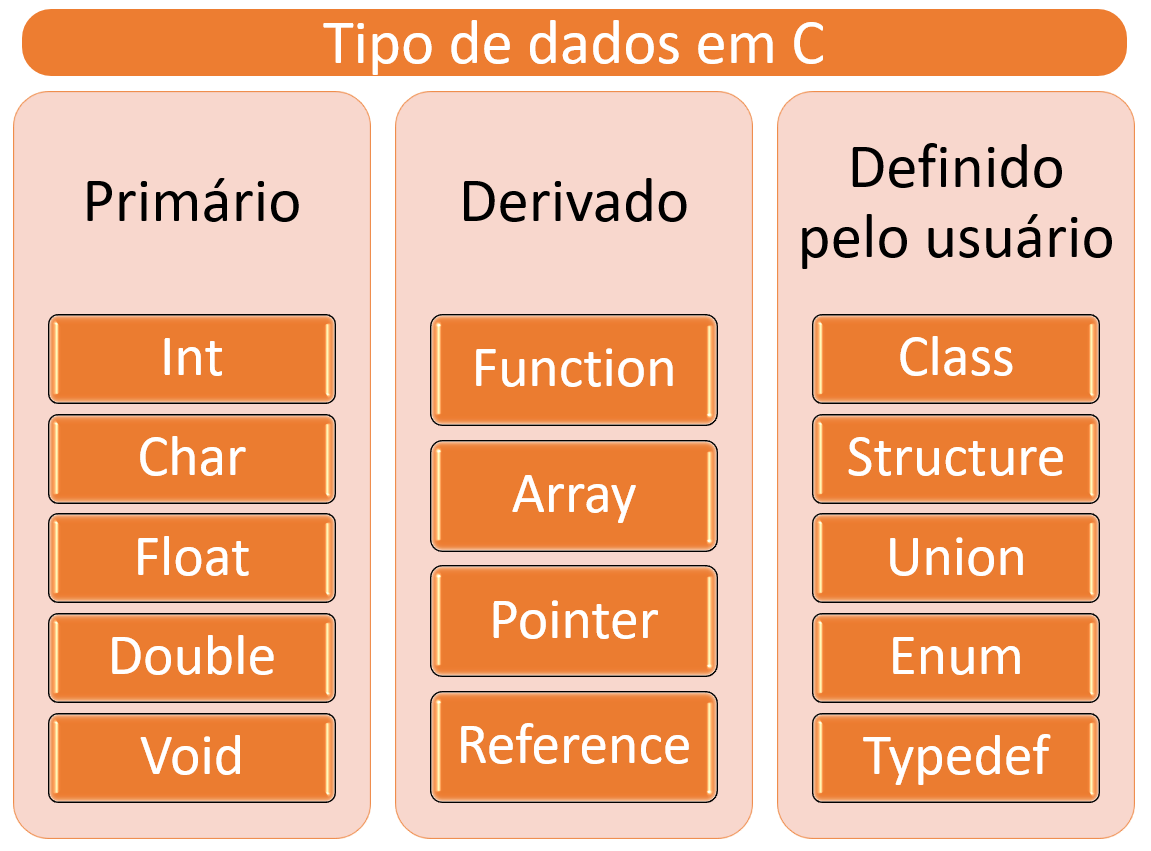
Quando consideramos o hardware do computador, o termo “tipo de dados” pode ser utilizado para classificar o tipo de informação que está contida em uma determinada célula de memória (inteiro, float, string…), sendo que esse tipo de dado é nativo do computador, ou seja, nessa abordagem, o conceito “tipo de dados”, é totalmente acoplado à arquitetura de hardware utilizada e o chamamos de tipo de dado Primário ou Primitivo conforme exemplificado abaixo:
Tipo de dados em C
Porém o conceito “tipo de dados” pode ser analisado sob uma ótica completamente diferente, desacoplando o seu significado das limitações impostas pelo hardware de uma arquitetura e aproximando esse conceito da função que deve ser executada.
Ao abstrairmos da arquitetura de hardware o conceito de “tipo de dados”, exemplificando, em uma operação de soma de dois inteiros, deixa de ser necessário descer ao nível de hardware e bits a fim de se conhecer detalhadamente o mecanismo empregado pelo computador para obter o resultado dessa soma.
Nesse caso utilizamos o hardware do computador para representar os inteiros e representar a execução da operação de soma entre esses dois inteiros, repito, sem conhecer os detalhes da implementação em hardware dessa operação.
Dissociado o tipo de dado da limitação arquitetural de hardware do computador, abre-se a possibilidade de representarmos uma quantidade ilimitada de tipos de dados e esse é o pulo do gato (jump of the cat).
Considerando abstrato o conceito “tipo de dados”, o dissociando das limitações de hardware e o empregando para definir um conjunto de definições lógicas, podemos então implementar por software esse conjunto de definições lógicas, a partir de um conjunto limitado de instruções de hardware, transcendendo as limitações do mesmo.
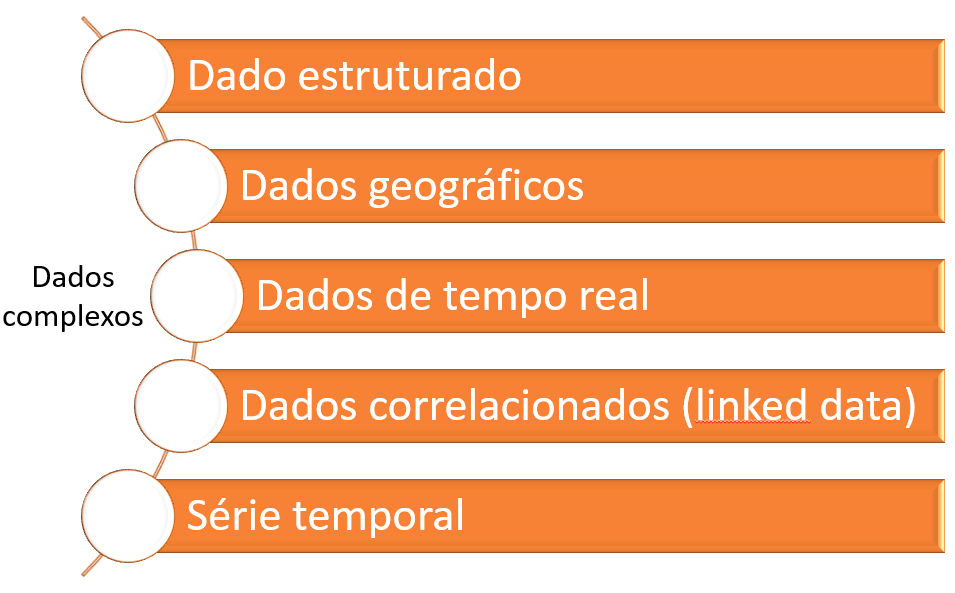
Estipula-se um novo tipo de dado, define-se suas características, especifica-se as operações possíveis a serem executadas nesse objeto e procede-se com a implementação em software do mesmo, a exemplo dos tipos de dados utilizados em Big Data, alguns listados abaixo:
Tipos de dados utilizados em Big Data
Fonte: TENENBAUM, Aaron M.; LANGSAM, Yedidyah; AUGESNSTEIN, Moshe J.. Estruturas de Dados Usando C. São Paulo: Pearson, 2013. 884 p. ISBN 13: 978-85-346-0348-5.