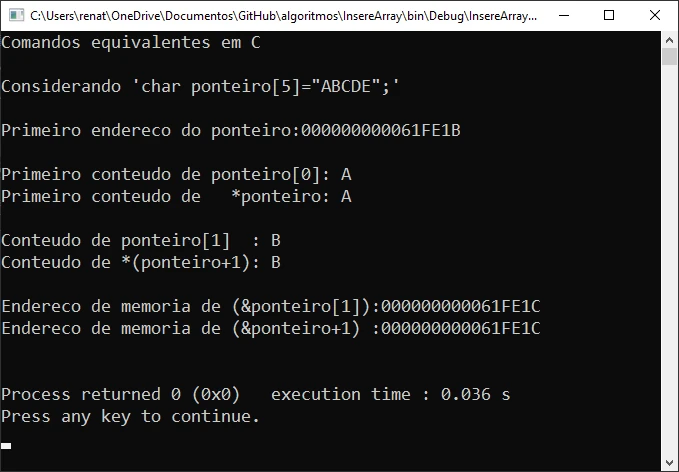
Olha. Eu gostaria de ter aprendido as diversas maneiras de se exibir tanto o endereço de memória como o conteúdo de memória apontado por um ponteiro.
Resumindo, seria mais ou menos o código abaixo. Se faltar alguma coisa, irei adicionando.
#include <stdlib.h>
int main()
{
char ponteiro[5]="ABCDE";
printf("Comandos equivalentes em C\n\n");
printf("Considerando 'char ponteiro[5]=\"ABCDE\";'\n\n");
printf("Primeiro endereco do ponteiro:%p \n\n",ponteiro);
printf("Primeiro conteudo de ponteiro[0]: %c\n",ponteiro[0]);
printf("Primeiro conteudo de *ponteiro: %c\n\n",*ponteiro);
printf("Conteudo de ponteiro[1] : %c\n",ponteiro[1]);
printf("Conteudo de *(ponteiro+1): %c\n\n",*(ponteiro+1));
printf("Endereco de memoria de (&ponteiro[1]):%p\n",(&ponteiro[1]));
printf("Endereco de memoria de (&ponteiro+1) :%p\n\n",(ponteiro+1));
return 0;
}
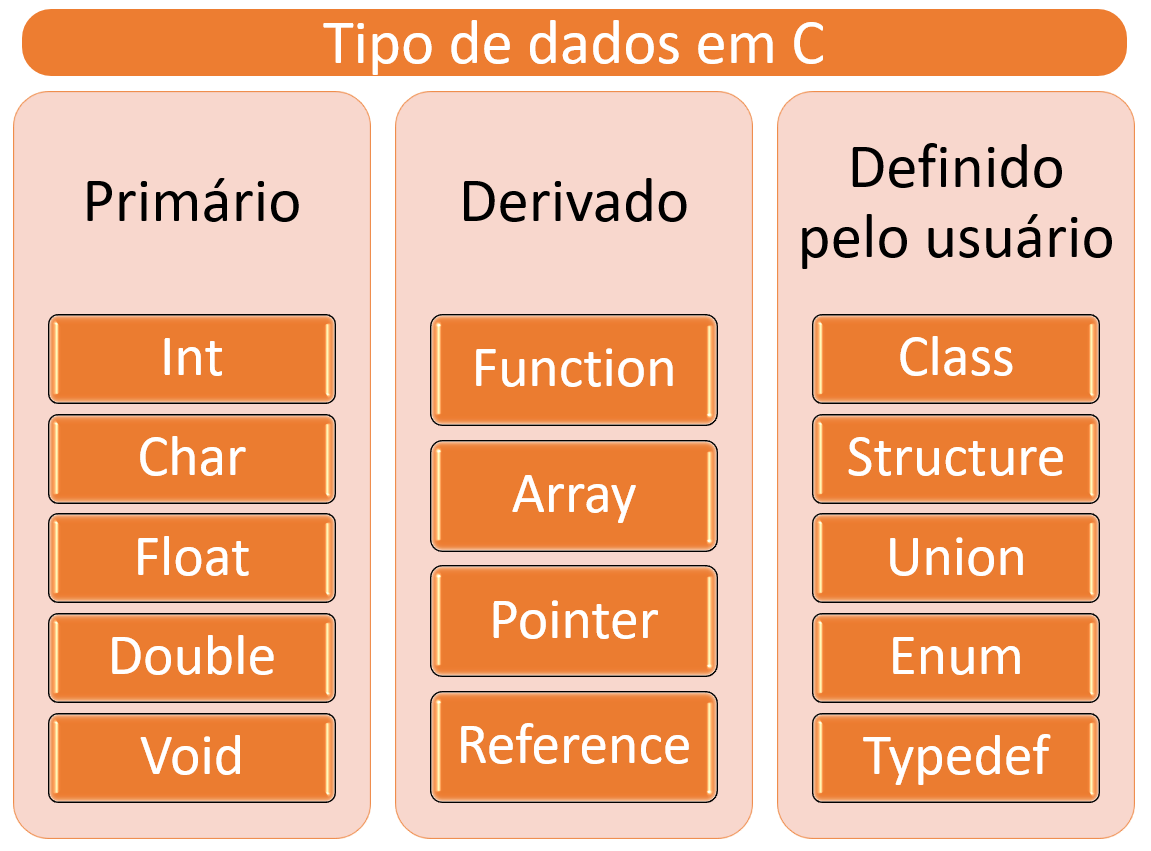
Quando consideramos o hardware do computador, o termo “tipo de dados” pode ser utilizado para classificar o tipo de informação que está contida em uma determinada célula de memória (inteiro, float, string…), sendo que esse tipo de dado é nativo do computador, ou seja, nessa abordagem, o conceito “tipo de dados”, é totalmente acoplado à arquitetura de hardware utilizada e o chamamos de tipo de dado Primário ou Primitivo conforme exemplificado abaixo:
Tipo de dados em C
Porém o conceito “tipo de dados” pode ser analisado sob uma ótica completamente diferente, desacoplando o seu significado das limitações impostas pelo hardware de uma arquitetura e aproximando esse conceito da função que deve ser executada.
Ao abstrairmos da arquitetura de hardware o conceito de “tipo de dados”, exemplificando, em uma operação de soma de dois inteiros, deixa de ser necessário descer ao nível de hardware e bits a fim de se conhecer detalhadamente o mecanismo empregado pelo computador para obter o resultado dessa soma.
Nesse caso utilizamos o hardware do computador para representar os inteiros e representar a execução da operação de soma entre esses dois inteiros, repito, sem conhecer os detalhes da implementação em hardware dessa operação.
Dissociado o tipo de dado da limitação arquitetural de hardware do computador, abre-se a possibilidade de representarmos uma quantidade ilimitada de tipos de dados e esse é o pulo do gato (jump of the cat).
Considerando abstrato o conceito “tipo de dados”, o dissociando das limitações de hardware e o empregando para definir um conjunto de definições lógicas, podemos então implementar por software esse conjunto de definições lógicas, a partir de um conjunto limitado de instruções de hardware, transcendendo as limitações do mesmo.
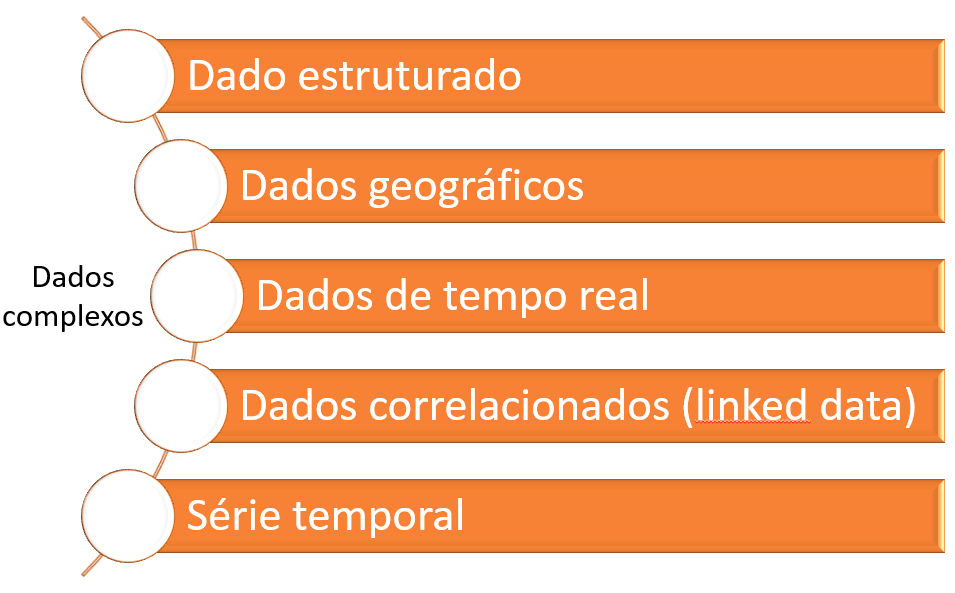
Estipula-se um novo tipo de dado, define-se suas características, especifica-se as operações possíveis a serem executadas nesse objeto e procede-se com a implementação em software do mesmo, a exemplo dos tipos de dados utilizados em Big Data, alguns listados abaixo:
Tipos de dados utilizados em Big Data
Fonte: TENENBAUM, Aaron M.; LANGSAM, Yedidyah; AUGESNSTEIN, Moshe J.. Estruturas de Dados Usando C. São Paulo: Pearson, 2013. 884 p. ISBN 13: 978-85-346-0348-5.
Responder essa, parece que estão querendo colocar os programadores em um patamar superior. SQN. Programadores precisam se dedicar muito nessa profissão.
A profissão de programador, como um todo, demanda que o profissional seja capaz de desmembrar tarefas complexas em passos menores e facilmente executáveis, utilizando uma linguagem extremamente precisa e que não admite erros.
Programas simples como solicitar que um led acenda ao abrirmos uma porta, demandam uma série de instruções que precisam estar ordenadas na sequência correta e devem ser sintática e semanticamente corretas.
Exemplificando, para o Arduino, um programa desses que acende ou apaga um led a partir do monitoramento de um sensor, seria mais ou menos assim:
#include <Arduino.h>
int ledPortaAberta=8;
int ledPortaFechada=10;
int sensorPorta=6;
#define DESLIGADO LOW
#define LIGADO HIGH
void setup(){
pinMode(ledPortaAberta, OUTPUT);
pinMode(ledPortaFechada, OUTPUT);
pinMode(sensorPorta, INPUT);
Serial.begin(9600);
}
void loop(){
if (digitalRead(sensorPorta)==LIGADO){
digitalWrite(ledPortaAberta, DESLIGADO);
digitalWrite(ledPortaFechada, LIGADO);
Serial.println("Porta fechada");
}
else {
digitalWrite(ledPortaAberta, LIGADO);
digitalWrite(ledPortaFechada, DESLIGADO);
Serial.println("Porta aberta");
}
delay(1);
}
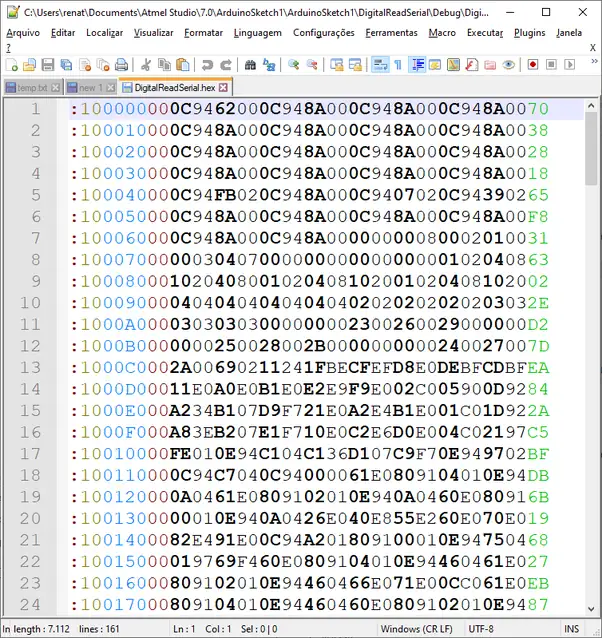
Conforme dito, o programa não deve ter nenhum erro sintático, caso contrário ele não ele não irá compilar e muito menos será possível gerar o código executável abaixo:
Ainda assim, não basta saber escrever o programa, colocar os comandos na sequência correta, seguir todas regras da linguagem, saber compilar, gerar esse código hexadecimal e até entender cada um dos comandos hexa acima.
O programa também tem que ser semanticamente correto.
A semântica, o sentido das palavras bem como a interpretação das sentenças e dos enunciados utilizados nessa linguagem acima devem refletir exatamente o que foi solicitado em linguagem natural, “quando uma porta se abre, um led se acende e quanto a mesma porta se fecha, o led tem que apagar”.
O trabalho do programador é converter um requisito em linguagem natural para a linguagem formal.
Esse trabalho de fazer a conversão e garantir que a semântica de ambas linguagens estejam alinhadas é onde está a arte e o desafio que programadores enfrentam todos os dias.
Dá para aprender, mas eu diria que poucos são metódicos o suficiente para tal.
É uma questão de perfil, nada mais.
Resposta originalmente postada no Quora em 29/maio/2020 e fonte da foto do teclado: https://www.cybercentralcorp.com/blog/
Se você instalou o Maven para Rodar com o Windows e está tentando usar o Oracle JDeveloper ou alguma outra IDE da Oracle e as coisas não estão funcionando muito bem, talvez seja a hora de ajustar algumas configurações no seu Windows.
Baixe o Maven do site da Apache próprio para o Windows, descompacte e mova a pasta com o Maven para a pasta Arquivos de Programas ou para o diretório de sua escolha.
Em propriedades do sistema do Windows, adicione a variável de ambiente M2_HOME com o valor do caminho do Maven
Adicione a variável de ambiente M2 nas variáveis de ambiente com o valor %M2_HOME%\bin
Adicione a variável de ambiente MAVEN_OPTS com o valor -Xms256m -Xmx512m
Adicione a variável de ambiente JAVA_HOME. Ela deve apontar para o diretório raiz do JDK (o diretório do JRE não serve para nada).
Inclua %M2% na variável de ambiente Path
Inclua %JAVA_HOME%\bin na variável de ambiente Path
No prompt de comando execute mvn –version para verificar se o Maven instalou ok.
O Game Design Document (GDD) é muito mais que um documento de conceito ou proposta de negócio.
É
normal que um GDD tenha algo entre 50 e passe de 200 páginas. O
propósito do GDD não é servir de apoio para vender uma ideia. Pelo
contrário, seu principal objetivo é ser um guia de referência ao
processo de desenvolvimento de um jogo (game).
O
GDD tem que focar no modo de jogo (gameplay), roteiro (storyline),
personagens, interface e regras do jogo. O GDD deve especificar o
projeto com detalhes suficientes e de tal forma que seja possível, em
teoria, jogar o jogo sem o uso de um computador.
Inclusive
poder jogar uma versão em papel do jogo construida a partir do GDD é na
verdade um modo barato de se entender e depurar o projeto do jogo. A
prototipagem em papel sempre deve ser considerada durante o processo de
desenvolvimento do game.
Devido
ao tamanho do GDD, um índice deve ser inserido logo após a página de
título do documento. Esse documento tem que ser entendido como parte do
processo de desenvolvimento do jogo e deve ser atualizado constantemente
à medida que o projeto é desenvolvido.
Como
boa prática deve-se ter certeza que o GDD esteja disponível a todos no
projeto de tal forma que os membros do time possam fazer as atualizações
conforme o necessário a qualquer tempo (obviamente um controle de
versionamento tipo GIT deve ser adotado).
O GDD deve conter em sua descrição basicamente os seguintes elementos, não se limitando à lista abaixo:
Interface do jogo
– indicando os elementos do jogo, tempo de produção, custo, requisitos
das interfaces, viabilidade da interface, audiência e gênero do jogo.
Mundo do jogo
– níveis e elementos presentes em cada nível do jogo bem como a
descrição dos mesmos. Inclui arte, cinemática, animações, itens
disponíveis e informações acerca de itens perigosos.
Habilidades dos personagens e itens – como funciona o ataque e defesa dos personagens, o que faz cada NPC, o que e como os personagens podem pegar de itens.
Game engine
– o que pode ser feito e o que não pode ser feito no desenvolvimento do
jogo. Esta parte do GDD serve para manter todos desenvolvedores
alinhados com os recursos disponíveis e comportamento geral do jogo
abordando tópicos como número de personagens por tela, animações por
personagem, restrições de câmera, paleta do mapa de textura e outras
informações que padronizem o desenvolvimento do game.
Você
utilizará como game engine a interface 2D do GameSalad, ou utilizará a
engine 3D do Unity? Sites exibidos logo a seguir. Essa decisão, por
exemplo, é definida na seção Game Engine.
Tenha
em mente que o GDD pode variar dependendo no nível de detalhes e
demandas do projeto, mas é para isso que ele serve e o que ele
basicamente deve conter.
Fonte: NOVAK, Jeannie. GAME DEVELOPMENT ESSENTIALS: AN INTRODUCTION. 3. ed. United States: Delmar Cenage Learning, 2012. 514 p. ISBN 13: 978-1-111-30765-3.
Ele faz o gerenciamento automático e dinâmico da memória da seguinte forma:
Aloca memória do e a devolve para o sistema operacional.
Gerencia a memória para a aplicação à medida em que a aplicação requisita memória.
Determina quais partes da memória irão permanecer em uso pela aplicação.
Realoca memória não utilizada destinando-a para outra aplicação.
O Java HotSpot garbage collectors empregam várias técnicas para melhorar a eficiência dessas operações, entre elas:
Utiliza
o algoritmo de reclamação de armazenamento de memória “generational
scavenging” em conjunção com métodos de datação dos dados na memória a
fim de concentrar os esforços nas áreas que contenham mais dados
suscetíveis a serem reclamados.
Utiliza múltiplas threads para
execução de operações paralelas, ou executa operações de longo tempo de
execução em segundo plano enquanto rodando uma aplicação principal.
Procura liberar grandes blocos contíguos de memória pela compactação de objetos ativos (live objects).
Qual vantagem de se utilizar o Garbage Collector?
A
vantagem de se utilizar o garbage collector é que ele libera o
desenvolvedor de aplicações da tarefa manual de se fazer o gerenciamento
de alocação de memória.
O
desenvolvedor é liberado da necessidade de cuidar das alocações e
liberações de memória e fica livre de ter que tomar conta das tarefas
que alocam dinamicamente a memória.
Isso
elimina completamente alguns tipos de erros relacionados a
gerenciamento de memória bem como otimiza o tempo de execução da
aplicação. O Java HotSpot VM possui um conjunto de algoritmos que
executam essa tarefa.