Meu professor de matemática pediu que eu arrumasse uma calculadora para fazer os exercícios da faculdade. Tem algum programa que emule uma calculadora para PC? – Pergunta originalmente postada no Quora e que replico aqui.
Professores irão me odiar!
Olha, normalmente os professores pedem calculadoras científicas que tenham funções básicas, tipo seno, cosseno, tangente, exponenciação e mais algumas outras funções.
Há vários emuladores que podem resolver o paranauê e existem várias opções.
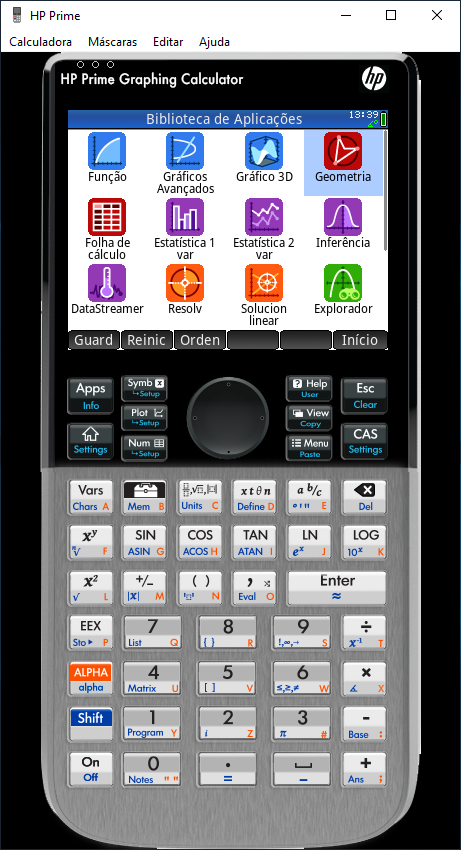
Se for um curso de Engenharia, talvez seja interessante considerar um emulador de calculadora mais porreta, e nessa linha eu sugiro o emulador da HP Prime Graphing Calculator, cujo print segue abaixo:
Imagem da HP Prime Graphing Calculator
Na verdade esse é um computador dedicado a fazer cálculos que inclusive é programável em Python.
O emulador dessa calculadora pode ser encontrado no site da HpCalc.org, cujo link para download da versão para PC segue abaixo:
Nota: Esse tipo de calculadora é complexa e precisa ler o manual para conseguir usar todas suas funcionalidades.
Caso queira algo mais simples, acesse o site HPCalc.org. Nesse site, você pode encontrar diversos emuladores das calculadoras da linha HP (alguns bem básicos) e centenas de programas e jogos para a linha de calculadoras HP.
Bônus:
Tem outro site, dividido em duas páginas que um serve para calcular a derivada e outro que serve para calcular a integral, cujos links seguem abaixo:
Esse site em particular é uma mão na roda porque ele desmembra a resolução dos cálculos passo à passo, inclusive indicando quais regras se aplicam a cada caso.
Nessas páginas web, preste atenção às abas de configuração das integrais e derivadas, que possui vários exemplos e opções de configuração:
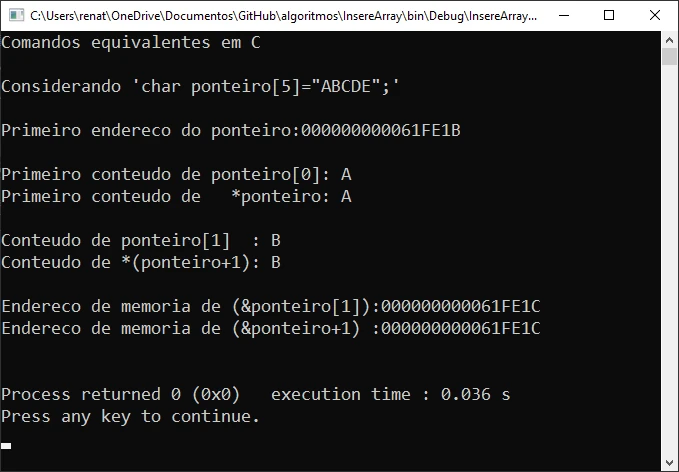
Olha. Eu gostaria de ter aprendido as diversas maneiras de se exibir tanto o endereço de memória como o conteúdo de memória apontado por um ponteiro.
Resumindo, seria mais ou menos o código abaixo. Se faltar alguma coisa, irei adicionando.
#include <stdlib.h>
int main()
{
char ponteiro[5]="ABCDE";
printf("Comandos equivalentes em C\n\n");
printf("Considerando 'char ponteiro[5]=\"ABCDE\";'\n\n");
printf("Primeiro endereco do ponteiro:%p \n\n",ponteiro);
printf("Primeiro conteudo de ponteiro[0]: %c\n",ponteiro[0]);
printf("Primeiro conteudo de *ponteiro: %c\n\n",*ponteiro);
printf("Conteudo de ponteiro[1] : %c\n",ponteiro[1]);
printf("Conteudo de *(ponteiro+1): %c\n\n",*(ponteiro+1));
printf("Endereco de memoria de (&ponteiro[1]):%p\n",(&ponteiro[1]));
printf("Endereco de memoria de (&ponteiro+1) :%p\n\n",(ponteiro+1));
return 0;
}
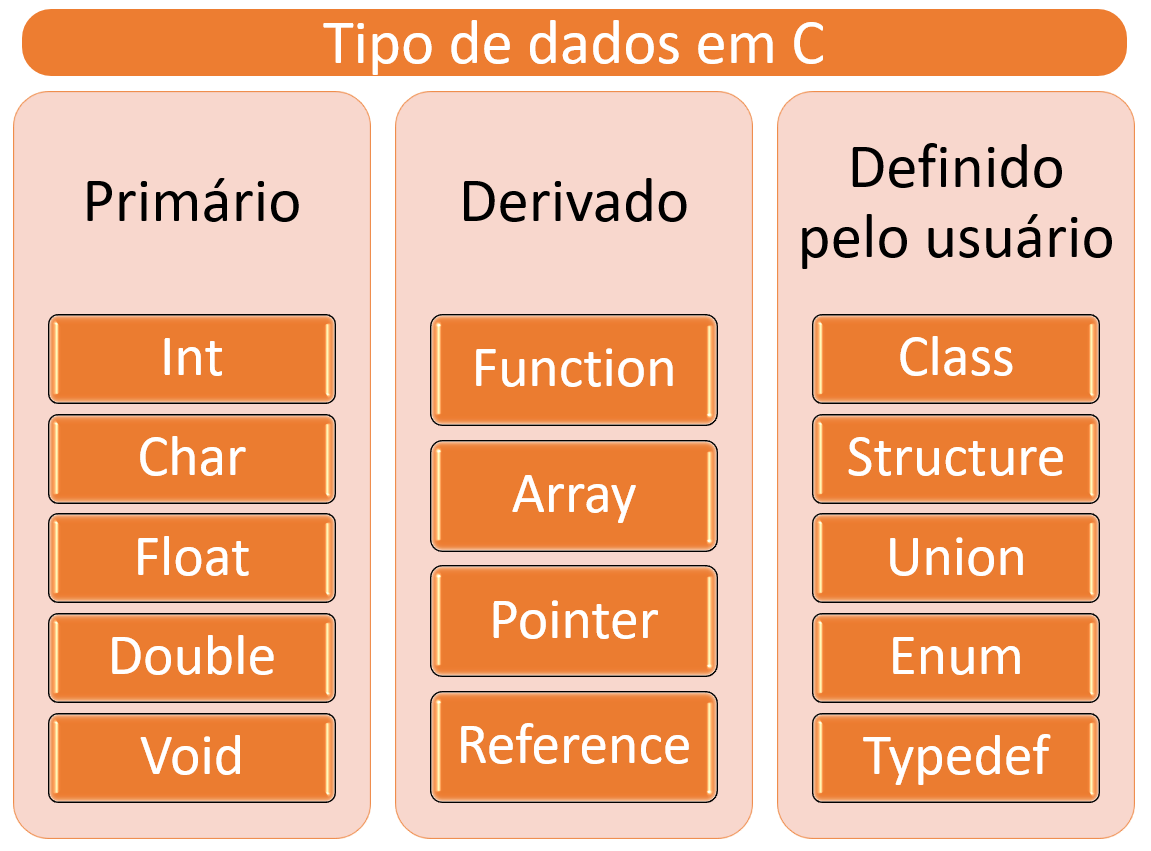
Quando consideramos o hardware do computador, o termo “tipo de dados” pode ser utilizado para classificar o tipo de informação que está contida em uma determinada célula de memória (inteiro, float, string…), sendo que esse tipo de dado é nativo do computador, ou seja, nessa abordagem, o conceito “tipo de dados”, é totalmente acoplado à arquitetura de hardware utilizada e o chamamos de tipo de dado Primário ou Primitivo conforme exemplificado abaixo:
Tipo de dados em C
Porém o conceito “tipo de dados” pode ser analisado sob uma ótica completamente diferente, desacoplando o seu significado das limitações impostas pelo hardware de uma arquitetura e aproximando esse conceito da função que deve ser executada.
Ao abstrairmos da arquitetura de hardware o conceito de “tipo de dados”, exemplificando, em uma operação de soma de dois inteiros, deixa de ser necessário descer ao nível de hardware e bits a fim de se conhecer detalhadamente o mecanismo empregado pelo computador para obter o resultado dessa soma.
Nesse caso utilizamos o hardware do computador para representar os inteiros e representar a execução da operação de soma entre esses dois inteiros, repito, sem conhecer os detalhes da implementação em hardware dessa operação.
Dissociado o tipo de dado da limitação arquitetural de hardware do computador, abre-se a possibilidade de representarmos uma quantidade ilimitada de tipos de dados e esse é o pulo do gato (jump of the cat).
Considerando abstrato o conceito “tipo de dados”, o dissociando das limitações de hardware e o empregando para definir um conjunto de definições lógicas, podemos então implementar por software esse conjunto de definições lógicas, a partir de um conjunto limitado de instruções de hardware, transcendendo as limitações do mesmo.
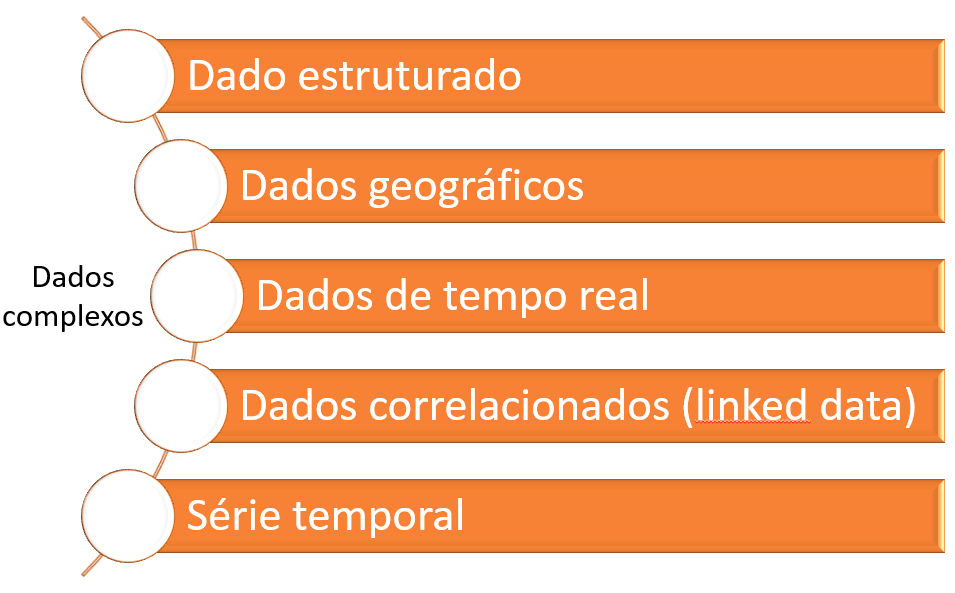
Estipula-se um novo tipo de dado, define-se suas características, especifica-se as operações possíveis a serem executadas nesse objeto e procede-se com a implementação em software do mesmo, a exemplo dos tipos de dados utilizados em Big Data, alguns listados abaixo:
Tipos de dados utilizados em Big Data
Fonte: TENENBAUM, Aaron M.; LANGSAM, Yedidyah; AUGESNSTEIN, Moshe J.. Estruturas de Dados Usando C. São Paulo: Pearson, 2013. 884 p. ISBN 13: 978-85-346-0348-5.
Aí galera, segue a minha visão sobre o assunto depois de dar uma lida no Sommerville.
Um
dos objetivos do processo de elucidação de requisitos é conhecer o
trabalho que os stakeholders (interessados no projeto) querem
implementar no sistema, de forma a ajudá-los em suas atividades.
Durante
a elucidação de requisitos, os engenheiros de software trabalham junto
com os stakeholders para entender o domínio da aplicação.
Os
engenheiros de software levantam as atividades trabalhadas, os
serviços, as funcionalidades que precisam ser implementadas no sistema,
bem com tomam conhecimento da performance desejada e assimilam as
limitações impostas pelo hardware, dentre outros pontos.
Dado
que pessoas, incluindo stakeholders, normalmente tem dificuldades em
definirem requisitos de forma abstrata, muitas vezes eles são levantados
a partir de exemplos da vida real, mais fáceis de serem obtidos.
Pessoas
são capazes de descrever como enfrentam situações particulares ou são
boas em descreverem como seria possível, a elas, melhorarem seus métodos
de trabalho.
Levantamento
de histórias e cenários é uma ferramenta poderosa para que engenheiros
de software capturarem esse tipo de informação, normalmente descrita em
linguagem natural.
De
posse dessas histórias e cenários, o engenheiro de software os utiliza
nas reuniões com os stakeholders para definir quais funcionalidades do
software devem ser implementadas e ou deprecadas.
Para saber mais:
SOMMERVILLE, Ian. Software Engineering: Tenth Edition. 10. ed. Boston: Pearson, 2016. 796 p. ISBN 13: 978-0-13-394303-0. –
Esses
dias eu estava acessando alguns sites e começou a dar aquele maldito
erro informando que a conexão não é confiável, cada vez que tentava
acessar sites do governo.
Isso
acontece porque o governo emite seus certificados de segurança e por
algum motivo o certificado raiz não consta na instalação do Windows e
Linux. Fica faltando e é uma droga.
Como faz para resolver esse B.O?
O
incomodado tem que sair procurando o certificado certo, fazer o
download e instalar. É um inconveniente no calor das entregas das
tarefas do escritório, fora que se formatar o computador, tem que fazer
tudo de novo.
Isso é um saco para quem manja de TI e deve ser Aramaico para quem é de humanas.
Esse funcionário público que teve essa ideia merece uma caixa de Bis de presente. Quem o conhecer, mande os parabéns!
Uma
vez encontrado um arquivo com todos certificados, bastaria descompactar
e instalar os certificados, mas aí o problema complica:
São 164 certificados (em 2022)!
Cada um tem que dar uma meia dúzia de cliques nos locais certos.
Se fizer errado, o certificado não instala direito, fica tudo zoado e não funciona.
Há risco de esquecer de instalar alguns certificados.
Há o risco de ficar reinstalando certificados já instalados.
O processo é demorado pra caramba, leva cerca de 1 hora por computador, muito tempo para uma pequena empresa, por exemplo.
“Ainda bem que sei programar” entra a partir desse ponto.
Após uma breve internetada, achei um script de PowerShell, o ajustei para as minhas necessidades e mandei rodar.
Como eu fiz?
O código pronto está aí embaixo. em linhas gerais:
Baixei e descompactei o arquivo em um diretório temporário
Abri o editor do PowerShell e naveguei até o diretório
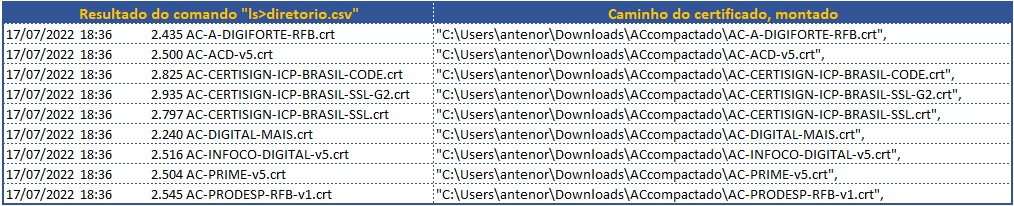
Dei um “ls>diretorio.csv” para listar o diretório em um arquivo csv
Abri o arquivo no Excel e com umas fórmulas, montei o caminho dos arquivos
Depois usei essa informação para montar o script
Instalou todos certificados de uma vez em menos de 1 minuto.
Na prática fazer isso pela primeira vez levaria o mesmo tempo que fazer manualmente, mas dessa forma todos certificados foram instalados corretamente (com certeza), com os cliques corretos e sem esquecer de ninguém. Fora que nas próximas, supostamente sofrerei menos com a instalação de certificados, fora que hoje 07/2022 eu tive de repetir essa instalação e rodou em minutos, pois eu já tinha feito o caminho das pedras 🙂
Programadores entenderão:
O script está aqui, é específico para minha máquina e não segue nenhuma das boas práticas de programação, mas resolveu o B.O.
O
OS Kernel ou Núcleo do Sistema Operacional é um programa de computador
que é o coração do sistema operacional de um computador. Ele tem
controle completo sobre tudo que acontece no sistema.
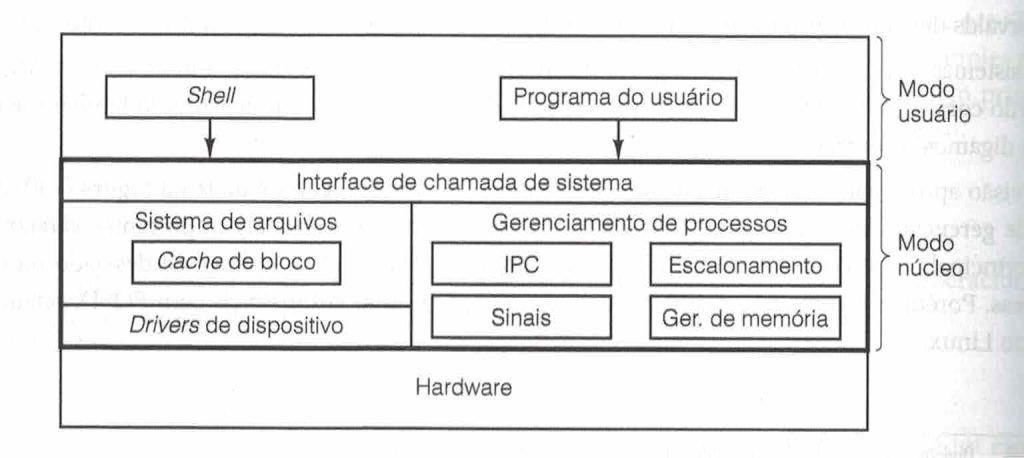
Abaixo tem a estrutura básica de um sistema operacional Unix, situando o modo núcleo.
Fonte: TANENBAUM
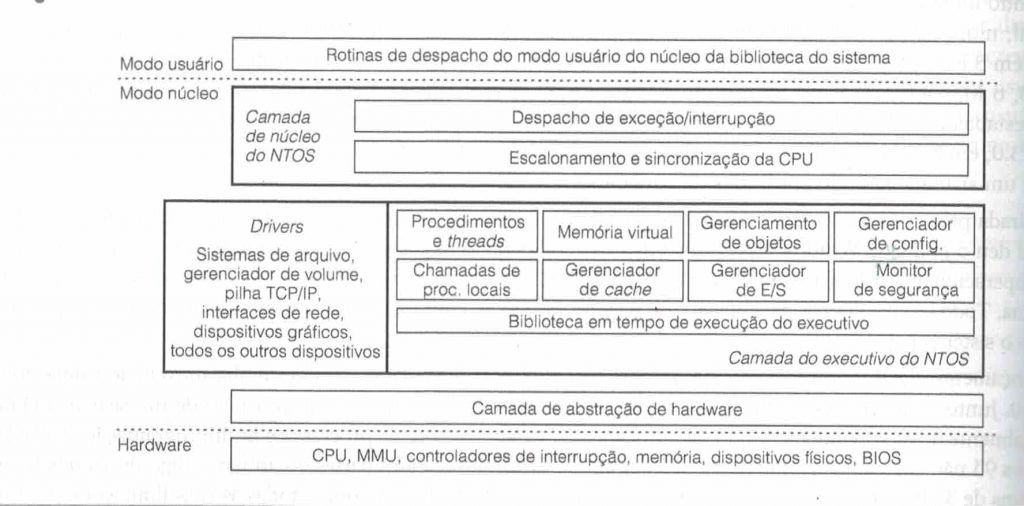
E aqui tem a estrutura básica de um sistema operacional Windows 7 situando o modo núcleo do sistema operacional:
Fonte: TANENBAUM
Na
maioria dos sistemas ele é um dos primeiros programas a serem
carregados na inicialização, logo após do carregador inicial
(bootloader). Ele gerencia as demais inicializações assim como as
requisições de entrada e saída do software, traduzindo-as em instruções
de processamento de dados para o processador do computador. Ele também
manuseia a memória e periféricos como teclado, monitor, impressoras e
interface de áudio.
O Kernel faz a interface entre o software da aplicação e o hardware do computador.
A
parte crítica do código do Kernel é normalmente carregada em uma área
separada da memória a qual é protegida de ser acessada pelos programas
ou outras partes menos críticas do sistema operacional.
O
Kernel executa suas tarefas como rodar processos, gerenciar
dispositivos de hardware com o HD, fazer o gerenciamento de interrupções
dentro da área protegida do Kernel.
Por
outro lado, tudo o que o usuário faz é executado na área do usuário
(user space) como escrever um texto no editor de texto, rodar programas
em uma interface gráfica (GUI) e etc.
Essa
separação previne que os dados dos programas do usuário e os dados do
Kernel acabem interferindo um no outro o que pode causar instabilidade
no sistema, lentidão no processamento, erros nos programas e até causar
erros catastróficos no sistema operacional.
“Nos
próximos 20 anos, a população idosa do Brasil poderá ultrapassar os 30
milhões de pessoas e deverá representar quase 13% da população ao final
deste período. Em 2000, segundo o Censo, a população de 60 anos ou mais
de idade era de 14.536.029 de pessoas, contra 10.722.705 em 1991. (…) Em
1980, existiam cerca de 16 idosos para cada 100 crianças; em 2000, essa
relação praticamente dobrou, passando para quase 30 idosos por 100
crianças. (…) a longevidade vem contribuindo progressivamente para o
aumento de idosos na população.(…) O grupo das pessoas de 75 anos ou
mais de idade que teve o maior crescimento relativo (49,3%) nos últimos
dez anos, em relação ao total da população idosa.”
Tá, estamos envelhecendo, e daí?
Não sei vocês, mas pelo menos para mim, ajudar idosos a operarem seus sistemas e aparelhos eletrônicos tem sido parte de meu cotidiano. É de tudo: WhatsApp, pagar e tirar segunda via de contas e particularmente, estou especialista em ajudar as pessoas a criarem seus próprios manuais de instruções acerca de como operarem seus televisores.
Anos
de experiência fazendo manuais de instruções, questionando requisitos e
testando aplicações para fazê-las fáceis para meus clientes.
Nunca
pensei que hoje em dia essa minha experiência profissional pudesse ser
utilizada, prosaicamente, para confortar o dia a dia dos mais
experientes que me cercam, daqueles do tempo em que televisor tinha
apenas o seletor de canais e o botão de liga / desliga junto com o de
volume, sendo que o resto ficava escondido para evitar confusão.
Publicado originalmente em 09/Fev/2016 no site nets-nuts.